
————————- 研发相关 ——————————————
阿里面试问题
(0) 先介绍2个简历上的项目,表达清楚(面试官会打断问他感兴趣的相关细节
(1) bloom filter 以及分布式相关处理(还得会大数据相关算法(那本书)以及hadoop spark storm)
相关参考1 相关参考2 相关参考3 相关参考4 相关参考5
(2) 各种排序算法(包括外部排序),尤其是针对链表的各种排序
(3) 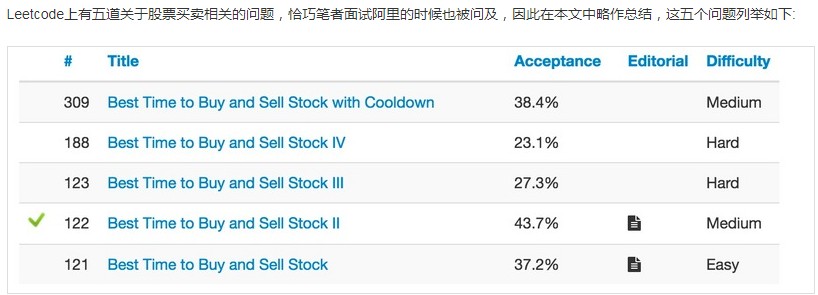
相关参考1 相关参考2
(4) 对称加密 非对称加密
(5) 2 ,3 ,4 次握手相关细节
腾讯面试问题
介绍自己的项目、难点在哪里、怎么解决的
介绍C++11特性
介绍fork函数
介绍time_wait状态
为什么tcp连接握手需要三次
介绍迭代器失效。push_back会导致迭代器失效吗。
红黑树的特征,介绍
哈希冲突的解决方法。
进程和线程的区别
你都使用什么线程模型
介绍协程
介绍快排算法
什么是稳定性排序,快排是稳定性的吗,为什么
快排算法最差情况推导公式
析构函数虚函数为什么
构造函数为什么不能是虚函数
打印在纸上的题目,考察:new [] 对象。static 成员。子类构造函数具体调用了啥。拷贝构造函数与赋值函数的区别。等号在拷贝构造函数出现的时机。什么时候需要赋值函数。深拷贝与浅拷贝。虚函数的调用时机。
笔试过程中(之前牛客笔试。面试官居然打印了我的笔试所有答案和结果,包括选择题和算法题,提交了多少次,失败了多少次)一道题的思路。考察虚指针的初始化时机。
随机出一道纸上的题目。给定前序遍历ABC后序遍历CBA,求中序遍历是什么,画出来两种情况。
笔试过程中(之前牛客笔试),第一道算法题的思路
有100个弹珠,双方轮流拿,每个人只能拿1~5个,无法拿的人输,必胜解法。若要赢,最后一次乙拿时,要剩下6个.
所以甲先拿4个
后乙若拿1个,甲4个
乙若拿2个,甲3个
乙若拿3个,甲2个
乙若拿4个,甲1个
乙若拿5个,甲5个
所以每一个两次都是5的倍数.
最后当拿完94个时,乙无论拿多少个,甲都可以拿掉最后一个.赢得比赛.
最近学什么(服务器编程)。之前学什么(TensorFlow),怎么学习的。你对Tensorflow强大的神经网络是怎么看待的。
家庭情况了解。
面试官话不多,答完很少继续追问。错了会引导你,张弛有度,不苟言笑,全程在打字(不知道在做什么)。
二面
面完特别难受,感觉自己实践太少了。什么教研室真是太耽误找工作了,天天被催搬砖。之前还不觉得,现在真是感觉考研教研室的话一定要找好的教研室才行。
成都4月13日
自我介绍
系统调用是什么。你用过哪些系统调用。什么系统调用会耗时长。
gdb调试用过吗。什么是条件断点。
函数指针和指针函数的区别。写个例子出来。
索引是什么。多加索引一定会好吗?(索引这个承认了看面经,但是后一个问题自己想出来了)
上一次面试中,你有哪些问题你回去查了。
上一次面试中,你的代码有问题,你知道吗。
你回答的问题是从哪里学习的。你这两天在干什么?
你能实习多久,你是来不了实习的吧,就算给你发了offer你还是要找导师同意才可以的吧。(说道这里好难受,没办法去实习,真的是,哎)
给你提一些建议,看下gdb调试,看下数据库知识,看下网络编程,多实践。
c++细节题
(0) 静态库和动态库的区别
相关参考1
=========== 机器学习算法 =============
先背景介绍下,LZ是PKU大四CS系,8月底去美帝读研。希望能在入学前攒经历,才想尽快去大公司实习,面试了一些公司,希望能回馈下。LZ本科有挺多科研经历,也有一点点论文发表,做了两个和NLP相关的项目,目前做的一个也打算投稿,所以申的岗位基本和NLP有关。以及大力给大家推荐B站的李宏毅机器学习/深度学习教程,对面试和科研感觉都很有帮助。
01
腾讯医疗AI实验室(已拿offer,决定去)
内推的是自己的学长。一面的是深圳分部的同事,人很好,自己正好有一点network让他认识了我,所以就捞了简历。面试内容很大一部分都是详细问了做过的项目,包括每一步是如何实现的,想法怎么来的。涉及到NLP的问题,问了有word2vec skip-gram的原理,negative sampling怎么做,为什么这么做,如何加速word2vec的训练。attention的机制,lstm和gru的原理,为什么可以解决梯度消失的问题。以及对于我做的一个跨语言情感分析的项目,还详细问了如何区分并提取每个语言不同的特征以及共同的特征。问了大约1h就说会尽快安排二面。
二面是同一天的晚上,是来自美国分部的同事,重点问了我之前发表论文的课题,包括我在其中负责的部分,对于时序数据的处理等。具体涉及NLP的问题,问了防止过拟合的做法,dropout的原理,batch normalization的原理,maxout激活函数的原理,因为我最近的课题用了Attent is all you need里的position embedding和Multihead的做法,他也详细问了各个步骤和原理,因为是晚上比较晚开始的面试,所以问了半小时就结束了。
hr面是第二天的晚上七点好像是,也是深圳的同事,问了简历中暑期科研的课题,我的背景,自己希望的工作地点这样。
然而等offer等了11天。。虽然中间有清明,但是流程还是过了很久。
02
滴滴时空深度学习算法实习生(已拿offer)
这个是急招的岗位,虽然没有内推但是很快就安排了面试,滴滴真的感觉是技术强,氛围好的公司,虽然没有面试间大雾(:з」∠)。
一面就是其他部门主管,我后来才知道,问的真的很详细很具体了。从我做的CNN开始问,用什么写的,kernel size是多少,把我项目里的CNN画出来,分析每一步的复杂度(就是W和b这种)。attention机制,如果有一维特别大怎么办,sgd、adagard、adam的原理,前两个要求推导。lstm和gru的原理,为什么可以解决梯度消失的问题,还画了computational grap并推了jacobian矩阵。ex的泰勒展开。word2vec的原理,negative sampling,画出示意图,推导公式。然后算法题写了一个递归,忘记具体题目了。
二面是这个部门的主管,真要命,但是问的东西更实际,直接就问了我实习的目标和要求,然后给了这个实习具体场景的问题,就是建模给起始和终点,判断这条路有没有可能被选中,我想了很久给了一个stack rnn的做法,面试官比较满意,就直接说挺好通过了。
第二天hr就电话联系商量入职,真是体验很好了,以后毕业还想来滴滴,如果能是新锐就更好了。
03
三星研究院(已拿offer)
当时同学怂恿投的,面试的感觉和别的公司都不太一样。
只有一面,但是有两个面试官。首先是30min做一套感觉是高中概率题。然后更考验工程感觉,因为项目是拿TensorFlow写的,现场用TensorFlow要求写一下逻辑回归,然后推导下逻辑回归公式,用最大似然就行。然后dropout中keep_prob是保留还是丢弃,Attention机制详细写下原理和公式,multihead的怎么做,这个能解决什么问题,为什么还要position embedding,还写了欧拉方程。还是同样地画我项目里的CNN示意图,然后改了一下kernel和channel,算一下复杂度和输出维度。word2vec, glovec, fasttext的原理,前两个的区别和联系,还推了公式。
感觉面试官和和蔼,说了过去做的具体项目是和三星的语音助手相关的。
04
阿里(二面跪)
阿里是机器学习的岗位,而且在杭州,是暑期实习,好像部门要求的是暑期来实习,明年能入职。从实习时间和未来入职看都不太匹配,而且二面没有准备好其他的NLP相关问题,就问了一点点就挂了电话。
一面的时候详细问了项目,问了决策树的原理,rf、gdbt的优势和原理。问了word2vec,问了svm的原理,LSTM每个门的公式,有哪些optimazor,之间的区别和联系。算法题写了个trie树。
二面的时候只问了NER的经典做法,还给了淘宝一个实际情景的问题(好像是评论的排序),但是自己说大概率留美感觉面试官的态度就冷淡了很多,面试完就说了希望以后还有机会就知道凉了。
以上,祝大家offer多多。
————– 分割线 ————
(1)机器学习部分
1 逻辑回归部分
常问,推导要会
推导:https://zhuanlan.zhihu.com/p/34325602
2 SVM部分
常问,推导要会,精简版看下面链接,但是写的不是很详细,最好把cs229讲义好好看看
推导:https://www.zhihu.com/question/21094489 @靠靠靠谱 的回答
3 集成学习
常问,推导要会
bagging方法:看周志华教授的西瓜书
boosting方法:看李航的蓝书,特别的对于GBDT,这篇文章写的很清晰,推导相对简单
这里注意一下,GBDT有两种,一种是残差学习,一种是负梯度代替残差的版本(所以有个G啊),为啥用负梯度近似残差也是常问的,其实这个说法就不对,残差只是在loss用最小二乘时候的一个特例,对求梯度刚好就是,换成其他loss function就不对了,所以应该反过来说,残差学习只是一个特例,负梯度才是通用的
stacking方法:没有特别好的讲解,都看看吧,这篇还行
决策树:cart树是最常问的,详见李航蓝书,从推导到剪枝都要会
4 softmax
这个相对简单,这篇足够了
5 牛顿法和梯度下降
推导以及优劣比较,相对简单,直接看cs229讲义
6 交叉验证
相对简单,看这篇
7 正则方法
8 归一化方法
基础问题,随便那本书都有
9 SVD分解 PCA ICA 白化
这部分我没有被问到,但是应该会问,毕竟是重点,看cs229讲义
(2)深度学习部分
1 过拟合的起因,怎么解决
这个没啥好说的,任何讲深度学习的书和课程都有,看哪个都行
2 batch normalization
这个问题下的回答很有价值
3 cnn rnn本质
这篇文章总结的很好
4 梯度弥散/爆炸
没有太好的文章,看看这篇讲resnet的吧
5 激活函数,比较
sigmod tanh relu maxout… 好多,这个随便一搜就一堆,放一个不太切题的文章吧,我偶像何之源奆佬的回答,手动滑稽
6 梯度下降优化
这就很多了,lan大神的花书讲的就很好,博客也可以看这个
7 各种网络结构
这个就太多了,cnn的 rnn的,细分还有很多,多看多熟悉吧
(3)传统算法
很奇怪,反而这块很不重视,考的题都很简单
1 阿里在线编程测试
给一个圆,切成n个扇形,涂m种颜色,要求任意两个相邻扇形颜色不同
思路:首先不考虑首尾位置的扇形是否颜色相同,那么总共是m*(m-1)^(n-1)种,
此时两种情况:1)首尾位置扇形颜色相同 2)首尾位置扇形颜色不同,第二种满足题意,不管,第一种可以把首尾颜色相同的扇形合成一个扇形,这样就成了一个相同要求但是规模是n-1的问题,这样递推公式就是f(n,m)=m*(m-1)^(n-1)-f(n-1,m) ,
2 腾讯二面 面试官随手问的一个问题
是分水岭算法的一部分,问题可以如下描述:假设有一个单通道图片,背景像素点值为0,中间的物体像素点值为1,求出所有物体像素点到背景的最短距离
思路:dp思想,查看邻点,如果有一个是0,那么距离为1,否则该点的距离是邻点中最短的距离+1,先扫描行,只关心行的不关心列,算出最短距离,再扫描列,只关心列不关心行,更新上一步扫描行后的结果,就是EDT算法,如果是欧式距离还要扫描斜边
3 腾讯二三面之间的笔试题
有n堆石子,第i堆石子的重量是w[i],每次合并两堆石子,并计算分数,比如,两堆石子是x,y,合并后是x+y 分数是xy,一直合并下去,直到只剩一堆石子,求最大累积分数
思路: 一眼看到合并就是哈夫曼树呗,区别就是哈夫曼树分数是x+y,这个是x 一眼看到合并就是哈夫曼树呗,区别就是哈夫曼树分数是x+y,这个是x*y,那么每次取两个最大就行了,优先队列,弹出两个最大的相加计算乘积分数,然后结果扔进队列,直到队列只剩一个元素
(4)数字图像处理和模式识别
这部分只被问了这一个问题问题
1 Sobel、canny 算子 边缘检测算子看这个
(5)信息论
信息熵、条件熵、互信息、信息增益 等等的计算,腾讯现场笔试考的,具体的题忘了。。。
(6)概率论
1 概率分布的相关计算
2 假设检验
这部分看看本科的课本吧,都有的,概率论的题考的比较活
@@@@@@@@@@ 分割线 @@@@@@@@@
从春招到秋招
算法工程师养成记(阿里+腾讯+其他)
作者:老班长
来源:牛客网
自我介绍:
大家好,我是老班长,一名老牛油(至于多老呢?我基本是第一批关注牛客网的同学,我加牛客网qq1群的时候,群里只有400多人(现在估计10多个群了吧),那时的产品经理是兴宝,哈哈,估计很多人不知道吧)
一直在牛客刷题,也听了不少左程云老师的算法课,受益匪浅,本篇面经作为一个回馈吧,感谢牛客,希望牛客越来越牛。
春招拿到了阿里实习offer,腾讯WXG劳务实习生offer
秋招(就是现在)拿到了腾讯MIG核心部门的offer,搜狗搜索SP(算是吧)
学校这块(部分人关注点比较奇怪):
本科东北大学(信息安全)
研究生哈工大(PR+ML+DL)
1
春招过程
投了阿里,腾讯,今日头条,美团,滴滴,搜狗,接下来挨个说吧
阿里一面(电面,45min)
自我介绍(学校学习课程和项目)
看过哪些书?说了一堆(西瓜书,李航之类的)。
说完,面试官疑惑的问:你没看过PRML?
黑人问号,赶紧把吴恩达视频和cs231n拿出来压压惊(后来实习才知道,面试官正在看PRML这本书)。
说了一下大致的项目,大概介绍一下(面试官评价基础很扎实)
问了loss优化方法,说了BGD,SGD,各自优缺点,优化方向(Adam之类的)
问了一个开放题,说是考验一下我的反应能力(阿里确实比较喜欢脑子灵活的同学)。
题目:用户打开一个App时,我们可以得到用户的坐标(经纬度),那么如何根据经纬度得到城市名称呢?
回答:没有预先定义的数据库,智能调用高德等第三方接口(因为高德被阿里收购了嘛)
不要求做高精度定位,可以将大城市为中心构建区域块(所有区域块内的经纬度映射到这个城市。这种题目要紧密集合业务来说)
阿里二面(电面,50min)
自我介绍
项目问问
你了解决策树吗?
回答:ID3+C4.5+优缺点+树的融合(GBDT,RF)+我的实现。
这里注意,面试官只问“你了解决策树吗?”,我的回答比较丰富,这里面试的一个tips就是,要尽可能主动的向面试官灌输你会什么内容,做好知识输出。
L1 L2了解吗?
回答:L1 L2的作用,为什么有这样的作用?一般求L1的优化方法(坐标下降,LARS角回归)(面试官一脸懵逼,你们老师这都讲吗?我说我是自己看的。。。深藏功与名)
链表逆序你会吗?
回答:非递归+递归
开放题,如何判断一个query是时效性query(答得比较差,就不贴了)。
为什么面算法会有这种问题?因为面试官原来是做搜索的,专门搞时效性query,mmp。
阿里HR面(视频,10min)
自我介绍,讲一下你的优势,你对我们团队了解吗?blabla,10分钟搞定。
腾讯OMG内推一面(视频,60min)
上来就问项目,从头说到尾
说一下LeNet的网络结构,一层层说,带着卷积核大小,越详细越好
项目里采集数据的流程
问kaggle比赛的项目(竟然不知道kaggle是啥,醉了)
kaggle项目里如何处理数据,计算特征相关性用什么办法
缺失值怎么处理?验证集怎么划分?哪些指标说明你的模型调优了?调节过模型的哪些参数
过拟合的标志有哪些?
决策树如何后剪枝
编程题,2sum(恩,面试官不同C++11语法)
腾讯OMG内推二面(视频,30分钟)
妹的,8点打电话,让我准备环境,8点半视频面试,真着急
上来编程(然而一些特殊情况没有考虑到,在面试官的提醒下也没做出来,我就知道内推凉了,怪我菜,认栽)
什么是Kmeans,与EM怎么联系
介绍下决策树,说一下属性选择方法
说下PCA
第一个编程题你会了吗(mmp,就顾着回答你问题了,我哪有时间思考?不会,然后挂了)
腾讯线下面试WXG一面(现场,90min)
因为腾讯每年都要来哈工大线下面试,所以相当于多了一次机会
面试官在处理公司的事儿,等了很长时间
上来给了一页题目,指了两个,你先做着吧,我这还有点事儿。一道题目是智力题,64匹马,8个赛道,找出最快的4匹马。
编程题是类似于一个归并排序的东西。(写面经的时候,被实验室ACM大佬看到了,甩了我一句,你考虑过4个赛道怎么解决吗?给跪了)
项目说一遍,老生常谈
BP神经网络推导一遍
其他细节记不清了,反正都是基础就对了
最后补了一句,你要是会点NLP知识就好了
腾讯线下面试WXG二面(现场,40min)
进了房间,跟面试官对视了十几秒,面试官开口了:你怎么这么被动,要回推销自己,ok?
然后我就开始了我得表演,从决策树到SVM,从BP到CNN,基本上把我会的都喷了。
面试官感觉我刹不住车了,然后就叫停了。问了一道题,随机数1~5,如何生成随机数1~7
腾讯线下面试WXG HR面(现场 ,20分钟)
你对机器学习的理解
除了CNN还熟悉其他深度学习模型吗?
学校情况(导师是谁,腾讯的HR很关心你的导师是谁?)
你有什么想问的?
最终,经过煎熬的等待,给了劳务实习生offer(劳务这种,比较坑人,幸好没去,类似外包,建议大家也不要去)
美团面试
阴差阳错,师兄给投成了“应届生春招找工作”这种情况,经过多方沟通无果后,没能得到美团的面试机会。
今日头条
笔试挂
滴滴
二面挂(可能是方向不太符合,一直问题python和C++底层原理的内容)
搜狗
投的太晚了,没有面试机会
2
秋招过程
秋招投了腾讯(提前批),今日头条,百度,美团,京东,搜狗,freewheel,Amazon
本来在阿里实习,转正答辩通过,可以拿到offer,但是base地在杭州,与我的意向不是很符合,所以放弃了。不过在此感谢实习期间所有的阿里师兄对我的帮助,阿里的项目经历也成为我秋招面试时的宝贵财富。
腾讯MIG一面(电面,40min)
只说了阿里的项目,就结束了。
腾讯MIG二面(电面,40min)
阿里的项目,然后聊聊对推荐的认识,谈话内容主要集中在推荐领域
编程题:怎么判断链表是否有环,还没说完,面试官就说不用说了,你有啥想问的,哈哈
腾讯MIG三面(电面,50min)
这一面,比较困难,因为面试官完全不看简历,完全不用你做自我介绍,上来直接开始怼
SVM与LR的优缺点(竟然还有人问这种问题)
SVM与LR的应用场景,那么更适用于这种场景?
GBDT,RF,XGboost相关
特征提取方法,如何判断特征是否重要
如何采集样本,样本类别不均衡对模型有什么影响(此时,面试官一度怀疑简历上的项目是否是真的)
其他的一些细节问题,在你的回答里挑问题,不是主动问的(所以TIPs是:可以通过自己的回答来引导面试官的面试方向,但是要有度,否则容易引火烧身)
编程题目:有序数组的交集(这个算法主要是搜索领域经常用,如果能给出在搜素领域的优化方式,那就能拿下这个面试官了。可惜太菜,我只给到了O(n)的时间复杂度)
最后补了一句:前面答的还不错
腾讯MIG四面(视频,30min)
这一面应该是技术总监,不会怼人的那种
基本就是聊聊项目,最近看什么论文?(是否关注论文这点很重要,反应你对前言技术的关注度)
技术的大方向,不会问具体的细节
所以比较轻松
腾讯MIG HR面(电面,20min)
了解你本科学校,研究生导师(腾讯HR真的很关心导师是谁)
为什么选择推荐方向
实验室的工作,扮演的角色是什么?
你有什么优缺点,
确定意向
另外提一句,9月11二三面,9月12四面,HR面,说是为了在笔试前走完流程,直接累的我腰疼。
今日头条
还在实习的时候,今日头条就开始提前批了(需要白金码)。本来有一个白金码但是因为还没准备好,所以没投
后来面试的同学都拿到了offer,就慌了,于是匆忙的内推了一份
笔试挂(两次笔试都挂了,足以证明我就是个菜鸟)
美团
一面讲了项目。然后面试官开始问你会不会这个东西,你只需要回答会或者不会,不需要具体讲解(可能面试官比较信任吧)
后来因为拿到了腾讯的offer,所以就推掉了之后的面试(面试官还问美团匹配和腾讯一样的岗位,你考虑吗?哈哈,这样的感觉真好)
搜狗
一面,项目+编程题(数组中第一个大于等于K的数,判断树是否相等(同构+对应节点值相等))
HR面也推掉了(很抱歉搜狗了,那边邀约了很多次,一直让我考虑搜狗。搜狗也很优秀,但是还是更喜欢腾讯的岗位,只能抱歉了)
Amazon
外企特点是连续两面,绝不拖泥带水
一面主要聊项目。面试官比较慈祥。因为二面面试官还在面试,之后聊了一些学校的事儿。期间一直询问是否愿意做软件开发(果断不妥协)
二面,聊了一下项目。然后问了一些基础东西(C++虚函数+原理,实现ls功能,LCA(树中两个节点的最低公共祖先))
目前还没结果
FreeWheel
之前没听说过这家公司,不过据说是一家不错的外企
一面,主要说项目,然后英语“谈笑风生”了一段
二面,又说了一遍项目。编程题(有序数组的交集,是的,和腾讯问的一样),然后又谈笑风生了一段
目前还没结果
其他的都是投了,但是还没有面试,估计不会面了。
3
面试总结
实习经历可以是一个金钥匙
从上边的面试经历可以看得出,春招面试还是比较痛苦的,一般时间较长,且大多数时间纠结在基础知识。所以春招的面试准备重在基础和刷题,因为大部分人都没有项目经历,所以只能靠基础知识评价你的能力了。
春招如果能拿到一个不错公司的offer,并做了一个较为完整的项目,那么恭喜你,秋招很简单。
比如我的阿里实习经历,面试官看了项目以后就默认你有了较为扎实的理论基础(毕竟去BAT实习的还是少数啊),大部分考察你的实践能力,也就是问项目。
简历
项目一定要真实具体。一个项目能够完整的从头到尾叙述下来,对于其中各种出现的问题,要有合理的解释。你在叙述项目的过程中,面试官会随时打断你,问你为什么?胡乱编个项目蒙混过关?不存在的。
如果是现场面试的话,一定要画结构图。因为面试官也是普通人,听你说一遍,并不能对你的项目有一个直观的认识,所以画图最好
最容易忽略的两个点:
一是项目来源,项目背景
二是项目的创新点
大多数人在复述项目的时候一再强调各种花里胡哨的技术,这会另面试官反感的。阐述项目来源会让面试官更容易理解你项目的意义,否则说了半天,面试官不知道你在解决什么问题,那就囧了
其次最重要的是创新点,或者解决了哪些难点,如果一个项目很简单,或者是已经有成熟的解决方案,那你的项目意义在哪里呢?
如果你的目标是算法工程师,就不要让社团活动、优秀班干部占据太多的篇幅,一页简历空间就那么大,在有限的空间里尽可能展示自己的技术实力。
我理解等面试结果的你
等面试结果是痛苦的,我经历过两次。现在牛客里流传“终于收到某某公司的短信了”,结果一看是业务推销短信。然后大家一致评论“又疯了一个”。很有意思
正视自己。不排除有非本人因素造成面试失败的,但是这绝对是极小概率事件。通常来讲,面试失败了,还是因为你某些地方还没理解透。你可能SVM推导卡在了一个步骤上,然后你抱怨说我只要看一眼书就会了,但是对不起,面试官认为你是比那些能顺利推导的同学是差一些的。
给明年的你
成为算法工程师,应该学习哪些东西:
首先说算法工程师有几个方向:NLP,推荐,CV,深度学习,然后结合公司业务做得内容各不相同
传统机器学习算法:感知机,SVM,LR,softmax,Kmeans,DBSCAN,决策树(CART,ID3,C45),GBDT,RF,Adaboost,xgboost,EM,BP神经网络,朴素贝叶斯,LDA,PCA,核函数,最大熵等
深度学习:CNN,RNN,LSTM,常用激活函数,Adam等优化算法,梯度消失(爆炸)等
推荐系统:itemBasedCF,userBasedCF,冷启动,SVD(各种变形),FM,LFM等
NLP:TF-IDF,textrank,word2vec(能推导,看过源码),LCA,simhash
常见概念:最大似然估计,最小二乘法,模型融合方法,L1L2正则(Lasso,elestic net),判别式模型与生成式模型,熵-交叉熵-KL散度,数据归一化,最优化方法(梯度下降,牛顿法,共轭梯度法),无偏估计,F1(ROC,recall,precision等),交叉验证,bias-variance-tradeoff,皮尔逊系数, 概率论,高数,线性代数(像我一样懒的人,就可以遇到哪里复习哪里,:D)
常见问题(具体答案去搜知乎或者百度,最好能在实际项目中总结出来):
常见损失函数
SGD与BGD
如何处理样本非均衡问题
过拟合原因,以及解决办法
如何处理数据缺失问题
如何选择特征
L1为什么能让参数稀疏,L2为什么会让参数趋于较小值,L1优化方法
各模型的优缺点,以及适用场景
学明白上述所有内容你需要多长时间?反正我这么笨的人用了不到一年时间(我本科完全没接触过算法相关,完全是研一学的)
推荐书籍:
C++:《C++primer5》《STL源码分析》《深度探索C++对象模型》《Effective C++》《Effective STL》 (虽然有些书有点老,不过开卷有益吧)(其他语言就不管了哈)
python:《python学习手册》《python源码分析》《改善python程序的91个建议》(Python必须要会)
刷题:《编程之美》《剑指offer》《程序员代码面试指南》《leetcode》
算法相关:《统计学习方法》(这本多看)《数据挖掘导论》《数学之美》《田林轩视频》《吴恩达视频》《西瓜书》
简历项目
最好能有两个相关的项目,而且是有质量的,不要太水
没有项目的,可以去参见比赛(kaggle,天池),比赛成绩高,比项目管用。成绩不高的,一定要有自己的解决方案。
刷题
刷题是必须的,书目就是上边列的哪些
每天一道或者两道,风吹雨打也不能停。如果坚持住,一年后你就成了
其他
什么叫学透了,学明白了
别人问你问题,你能讲明白
躺在床上,闭着眼,能完整的阐述一个算法(什么是完整?以SVM为例,SVM的推导?KKT条件?什么是支持向量?什么是松弛变量?为什么推导成对偶形式?核函数的作用是什么?如何选择核函数?模型优缺点?)你说这些问题我都明白,但是你是否能形成一个知识体系呢?一提到SVM,就能想到所有这些问题呢?
能够达到第二步的要求,那么面试官在问“说一下你对SVM的认识”,你就可以滔滔不绝的讲了,这样面试官才能认可你,这样就很舒服了。
人脉太重要了
找工作时,互相帮助,多加几个交流群,观摩大佬的一举一动
多和上班的师兄沟通,因为他们能把简历直接给到leader手里
多向周围的大神学习。就像我实验室的ACM大佬,他是我让我佩服的五体投地的存在。每次有什么不会做的编程题,找他解释都是秒解。还要感谢实验室的师兄,带我项目,助我去阿里实习。
最后,感谢一年努力的自己(实验室的ACM大神说,你正以肉眼可见的速度成长)。没错,一年前的今天,我菜的不能再菜了,从一个算法小白,经过一年的努力还是能轻松拿到腾讯的offer。所以,你呢?
最近稍微清闲点(开题结束了,秋招也就这样了),所以大家有什么问题可以戳“阅读原文”留言或者私信,尽量帮大家点忙。
=============== 分割线 ==========
当时秋招的时候写的,只写了几个公司,后面面试的很多公司都没有写,先放上来,有空再回忆再更。
今日头条
1 一面:
挑一个你觉得做的最好的项目讲讲,然后问问题
讲一讲HOG算子(项目里有写),是怎么求梯度的?
讲一讲SVM,知道多少说多少,为什么要用对偶问题求解?
说一下BP是怎么求导的
讲一下PCA,讲完后问有一个XX’,为什么?为什么是方差最大?
写代码:二叉搜索树删除某个节点,先说思路,后写。
1 二面:
讲论文,用深度学习怎么做,有什么区别?
讲项目,有没有遇到hard example,对于这些怎么处理的。答曰调整了阈值,没有在训练层面处理。
如果要处理人脸识别的hard example怎么处理?答曰fine-tune,继续问训练样本怎么办?答:采集样本,然后data augmentation, GAN理论上也可以。他说GAN太难了。
在SVM的训练中有没有遇到hard example。答,SVM对hard example的应用非常重要,先用一部分训练集训练一个模型,然后用剩下的一部分训练集的一部分测试,把出错的再送进去训练,重复两到三次,效果会比较好。然后解释了为什么。
SVM加核函数用过吗?讲一讲其中的差别。答:训练样本多,维度较大就可以用核函数,如果样本少用核函数比较容易过拟合。
写代码:一个链表,依次输出第一个,倒数第一个,第二个,倒数第二个…这个简单。
1 三面:
稍微讲了一讲项目
直接写代码:
给一个float的数,求算术平方根。先说思路,我想的是在一个区域内随机打点,从0到x积分=根号x,结果就是根号x的导数,0.5/根号x,面试官说这个带来了新的根号x,不行,然后提示说直接求,然后我就想到了折半查找。0~x折半或者0~1折半,分x大于1还是小于1的情况。
写代码:
三种砖块,分别是11,12,13,拼成1N,有多少种拼法?我开头想成了完全背包问题,一开始写代码,说不对,想错了,就是一个斐波那契问题,很快写出,问,复杂度是多少?答O(N),问有没有更简单的?我当时确实不知道,然后就说我不知道。然后面试就结束了,没想到最终还是通过了三面。
携程
1 一面:
讲一讲生成模型和判别模型的区别。
GAN网络讲一讲,和生成模型以及判别模型有什么关系。
求SIFT算子的步骤,优化方法?没答上来,说了一个大概,忘了。。
要实现一个哈希表,应该怎么做(根据要哈希的内容选择合适的哈希函数和冲突解决方案,比如balabala…)
1 2面:
放弃
拼多多
1 1面(电话面):
牛顿法怎么求Hissen矩阵,知道拟牛顿法吗
代码,讲思路:若干个长度不同的数组,求最小的区间,让每个数组都有数字在这个区间内(不会)
换个简单的:一个01矩阵,每一排都是0在前1在后,问哪一排的1最多?(二分法)问有没有更简单的方法(每一排记录当前的最左边的1的位置,下一排的时候直接忽略右边的)问时间复杂度,猜测是O(m+n)
1 2面:北京现场
项目
会什么机器学习方法?讲一个。我挑了LR,从原理到推导到优化。他问梯度下降是最优解还是局部解,问,如何让它收敛到全局最优解?(不会)http://blog.csdn.net/itplus/article/details/21896453 牛顿法和拟牛顿法,拟牛顿包括BFGS和L-BFGS, 推导海森矩阵的逆之间的关系,绕开了求解海森矩阵。
写代码。若干个区间,只要区间有交集则可以合并,求合并后跨度最大的区间是哪个?(sort,合并)
1 3面:
项目
写代码:链表,原址变换为:奇数在前,偶数在后,相对顺序不变。(void 函数)
机器学习。。忘了
搜狗
1 一面:
项目问一遍,其中涉及的机器学习方法全问了一遍。
一个python的dict,按照key-value存储,如何按照value排序
如果是C++怎么做?一个map,怎么按照value排序?
static的类有什么用。
如何实现一个只能实例化一次的类。
模板类?
纯虚函数和虚函数的区别
深度学习是万能的吗?什么地方不适用,如果给你一个任务,你如何选择用深度学习还是传统的如SVM?(任务、数据量、数据特点)
SVM核函数的选择?多项式核和RBF核的关系?
resnet、inception,attention分别描述
按照你的经验,深度学习的待学习的参数量和训练样本数量之间的关系。
1*1的卷积核的作用
TensorFlow interactivesession 和 session的区别
RNN的缺陷以及LSTM怎么解决?
如何提高一个网络的泛化能力?
描述dfs和bfs,分别怎么实现?(栈和队列)
描述迪杰斯特拉算法
动态规划是什么
动态规划和带记忆的递归有什么区别?(自顶而下和自底而上)
0-1背包问题的动态规划递归式怎么写?
描述KMP算法
写代码:链表求和(反过来的)
写代码:三角数堆,只能往左下或者右下走,从堆顶到堆底和最小是多少。(dp)
1 二面:
项目、论文各种问,刨根问底。
数学&&智商题目:一个袋子里有100个黑球和100个白球,每次随机拿出两个球丢掉,如果丢掉的是不同颜色的球,则从其他地方补充一个黑球到袋子里,如果颜色相同,则补充一个白球到袋子里。问:最后一个球是黑球和白球的概率分别为多大?
数学&&智商题目:A容器中有4L沙子,B容器中有4L米,假设米和沙子密度一样。有一个C容器是300ml, 第一步,用C从A中舀300ml到B中,混合均匀,第二步,用C从B冲舀300ml到A中混合均匀。再重复第一步和第二步,问这四步之后,A中的米和B中的沙子谁多?
滴滴
1 一面:
项目相关的机器学习和深度学习
int *p=6; free(p)这段程序有没有错?运行会发生什么。
写代码:两个有序数组的合并
对强化学习了解吗?
1 二面:
项目。
你觉得滴滴打车的拼车价是怎么计算出来的,详细描述。(路径规划,订单预测之类的)
你觉得滴滴打车的溢价,1.1倍,1.2倍,这些数值是怎么计算出来的?(订单预测,当前司机数量),目的是什么?
推导PCA。
说LR和SVM损失函数。
代码:二叉树之字形层次遍历,(正反正反。。。)
1 三面(面试官像个部门领导,比较老一点,沉稳一点):
项目,涉及的深度学习和机器学习。
推导PCA,具体问很多为什么。为什么是方差最大化?你这个是方差吗?
推导BP神经网络的反向求导。(可以用均方损失函数)
代码:A和B是两个矩阵,求 tr(A’B),A’指A的转置。(写出来后,我没有检查AB是否size相同,他说应该考虑这种边界条件,并说你考虑了AB是否空矩阵这是比较好的一点)
XGBoost了解吗(No)
1 四面(HR):
最有成就感的项目,讲讲分工,为什么有成就感?
实验室同学们怎么评价你,他们认为你的优缺点是啥。
拿到什么offer。怎么选择公司?
对滴滴的了解程度,怎么评价滴滴。
============ 分割线 ==========
腾讯新闻算法实习面经
项目主要用到了gbdt和LR,主要问的这两个模型
GBDT每轮拟合的是什么东西,GBDT做分类问题时又拟合的是什么东西(当时懵了,拟合的是梯度嘛?)
缺失值具体怎么做的,怎么考虑
LR+L1作用
GBDT除了平方损失,还有什么损失函数
GBDT里的G代表什么,体现在哪里,XGboost在梯度上改进的地方
OneHot的作用:将特征映射到欧氏空间,更合理的计算距离或者相似度度量,表达上更合理
决策树不适合用onehot的原因:结点分裂时容易分散?不清楚
遇到一个具体问题时,选择什么模型,有哪些方面的考虑、依据
算法题:全排列、二分查找
============ 分割线 =========
本人会一直写到秋招结束,记录下参加的每场面试
如果回答上有什么错误,请不吝赐教哈!!! 谢谢1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
目前内推面了:
阿里(一面跪)、京东(offer)、拼多多(offer)、美丽联合(一面跪)、链家(offer)、美团点评(三面跪)
目前校招面了:
360(一面跪)、百度(一面跪)、三星研究所(offer)
据说可以攒人品~~~~~
转眼都到了2018年了。秋招都结束这么久了。最后拼多多也给了offer,不过太晚了,真奇怪这家公司,时间拖了那么久。
招聘结束后,不知道都忙了些啥,就到了这会儿。
前几天想编辑此贴,但被告知,加了精,没法编辑。好尴尬。刚才看到被解开了,这才过来编辑。
鉴于有许多人问关于招聘的一些问题。我就写一些招聘的一些事。包含一些经验之谈吧,用好了有奇效~~~在最后面~
刚去导员办公室领了三方协议。感觉秋招快要结束了。
唉,腾讯也没霸面上。。。
不过得提一下,三星研究所的效率真的挺高的。刚才打电话说了薪资,让签约。(也算是对周二面试有个交代吧)
效率真心高,而且笔试面试还有福利,送卡管午饭
尴尬了,前几天犯懒了,没及时更新百度的一面,直到。。。现在还没有收到下一面通知,应该跪掉了。这周二又面了三星研究所。
昨天傍晚,当小伙伴们都焦急的等待华为结果时,我很淡定(因为华为连面试机会都没有给我)。结果收到了意外之喜。
拼多多居然发意向书了,(这公司再不发,都忘了有这一茬了)。毕竟是对自己面试的肯定,还是挺开心的。
秋招快要结束了,霸面腾讯不知道还能不能安排面试,下午领三方1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35话不多说,百度一面,三星两面奉上。
上周收到了京东的offer。虽然之前有面试官的口头offer,但是正式offer下来,才安心嘛。
接到offer还是很震惊的。出乎人意料啊。
然后,晚上就吃了麻辣香锅~~~
犒劳自己~
昨天面了百度,第一轮。这是迄今为止经历过时间最长的一轮面试。足足整了1个半小时。
把我都快榨干了,会的几乎全都被问了,不会的也被问了。
不过确实学到很多东西,之前很多东西没有实际做过,只看理论,只是知其然,经过面试官的讲解才明白其所以然。
先去洗澡,一会回来更新~
上周末收到了链家的offer。还是蛮开心的。毕竟是准备这几个月以来的第一个结果。
当天晚上,就给自己加了一个鸡腿~~~
***继续努力,要让自己的能力尽可能接近用人单位所开出的工资的价值***
昨天早上搜狗一面,下午美团三面
昨晚百度做崩了。。。有道编程题脑袋秀逗了,搞错了
刚刚做了腾讯的,感觉真是画风新奇啊。跟其他公司那些浓妆艳抹的风格不一样啊。
没有编程,没有编程,没有编程
还有个求行列式的,略微尴尬啊
早上美团点评二面
因为要面美团,所以在牛客上找面经。
感觉应该把这几天面的写下来,不能等秋招结束再写了,那样找面经的同学(比如说我~)不就少了一篇面经可看嘛
因为时间紧迫,更新的问题没有详细解答。后面再来补
更新:链家二面、链家HR面、拼多多二面、拼多多HR面、京东HR面、360 一面、美团点评一面
记录一下链家的面试,本来准备把几面都写完。但发现写完一面,有种精疲力尽的感觉。。。
这是我目前为止经历过时间最长的面试。约1个小时多一点点。
后面再写二面、三面吧。一面够长的了。
感谢各位大佬捧场,一会记录下今天的面试
西安南雷村职业技术学院
—一个散养的没导师的硕。。。
以前玩大数据,现在玩机器学习,刚开始玩
开八:
2017-08-10-阿里菜鸟-机器学习-内推-1面-电话
没有自我介绍。。。直接略过。。。
1、讲一下你觉得你突出的地方,有亮点的地方。
说了SVM和LR
2、LR为什么用sigmoid函数。这个函数有什么优点和缺点?为什么不用其他函数?
3、SVM原问题和对偶问题关系?
4、KKT条件用哪些,完整描述
5、说项目
6、有一堆已经分好的词,如何去发现新的词?
面试官给的提示:用这个词和左右词的关系。互信息 新词的左右比较丰富,有的老词的左右也比较丰富。还要区分出新词和老词。
7、L1正则为什么可以把系数压缩成0,坐标下降法的具体实现细节
8、spark原理
9、spark Executor memory 给16G executor core 给2个。问每个core分配多少内存
面试官那边全程嘈杂,不知道在干啥,讨论问题??
2017-08-11-京东广告数据部-机器学习-内推1面-电话
1、自我介绍
2、说一下进程和线程
说一大堆,再就说之间的区别
3、线程安全的理解
4、有哪些线程安全的函数
5、数据库中主键、索引和外键。以及作用
一个表可以没有主键,可以有索引
6、说项目
7、Spark原理
8、Spark是多线程模式,怎么退化为多进程模式。
在每个executor core设置为1,即每个executor是单线程的。
9、撸代码。实现一个java迭代器
数据:
int[][] data = new int[][] {
null,
new int[] {1,2,3,4},
new int[] {},
null,
new int[] {5,6,7},
new int[] {8},
null,
};
要求:遍历是跳过NULL。依次遍历每个元素:1,2,3,4,5,6,7,8
提示:
hasNext里面不应该改变迭代器内部状态,hashNext只判断
next返回值,并且指向下一个有效元素。
P.S. 面试官很忙,在我写代码的时候。还在跟另一个候选人约时间1
2
2017-08-11-京东广告数据部-机器学习-内推2面-电话 一面、二面连着玩
1、自我介绍
2、对于机器学习你都学了哪些?讲一个印象深的
说了SVM原理,拉格朗日法,对偶问题,以及好处。
3、SVM怎么防止过拟合
说了SVM里面的松弛变量。不知道对不对
4、我主动出击,有另一大类算法决策树,说不管是LR还是SVM都不能直观的感受到决策依据。而决策树易于理解,能够直观的感受到决策依据。
说了划分依据:信息增益(说了信息熵的来源,等概率时熵最大)、信息增益率、基尼系数。
说了划分方法(基于信息增益的)
说了C4.5比较ID3的优点。
5、决策树如何防止过拟合
剪枝,前剪枝和后剪枝。说了REP剪枝。C4.5是悲观剪枝
6、项目没问,说从上位面试官了解了。
7、撸代码
求连续子数组最大乘积,还让考虑边界问题(最后问了:连乘有可能导致溢出,存不下了)
2017-08-15-拼多多-算法-内推1面-电话
1、自我介绍
2、介绍项目
3、项目延展题:电商搜索框,每天有500W的搜索query。针对新来的一个query,给出和它最相似的100个query。
如果用RNN分类模型表征,那么向量不应该用最后一层的分类特征。应该用倒数第二层的更纯的特征。
现在假设500W的query已经是向量了。如何和这一个query比较。全部算距离不行,开销太大。
应该怎么办???
4、K-means聚类个数选择,做什么样的试验来确定K
5、两个4G的文件(每个文件可能有重复),里面全都是数字。现有内存1G,求这两个文件的交集。
2个4G的文件,分别hash成10个子文件,一个400M。
把一个子文件存储到hash表中,作为key。遍历另一个文件,看这个数字是否存在于刚才的hash表中。存在即可输出。
2017-08-23-美丽联合-算法-内推1面-电话
1、自我介绍
2、介绍项目
3、说了SVM
4、为什么要把原问题转换为对偶问题?
因为原问题是凸二次规划问题,转换为对偶问题更加高效。
5、为什么求解对偶问题更加高效?
我答了,因为只用求解alpha系数,而alpha系数只有支持向量才非0,其他全部为0.
6、alpha系数有多少个?
我答了:样本点的个数
7、避免过拟合的方法
答了:决策树剪枝、L2正则和L1正则
8、为什么L1正则可以实现参数稀疏,而L2正则不可以?
答了:L1正则因为是绝对值形式,很多系数被压缩为0,。而L2正则是很多系数被压迫到接近于0,而不是0
9、为什么L1很多系数可以被压缩为0,L2是被压缩至接近于0?
答了:图像上,L1正则是正方形,L2正则是圆形。
L1正则的往往取到正方形顶点,即有很多参数为0
L2正则往往去不到圆形和参数线的交点,即很多分量被压缩到接近于0
哪位大佬知道哪里有L1、L2的实现代码???,求告知~~~
10、问平时用啥语言比较多?
说了之前用java、scala多。现在用python较多。
11、问jvm 啥啥啥(没听清)。。。
答:不会
12、python…直接问你个开发中的实际问题吧,如果写的程序跑的非常慢,多方面分析这个问题?
答了: 1、检查程序是否有多层嵌套循环,优化
2、检查程序是否有很耗时的操作,看能否优化为多线程并行执行
3、检查数据量是否非常大,考虑是否可以用分布式计算模型。
求大佬补充~~
13、SQL中inner join 和outer join的区别?
14、试图给他说说SPARK,结果被严词拒绝(开玩笑的)。。。说时间紧迫,还是他来问吧。。。
15、Kmeans中,现在给你n个样本点不在欧式空间中,无法度量距离。现在给了一个函数F,可以衡量任意两个样本点的相似度。请问Kmeans如何操作?
答:想了一会,比如K=4的聚类。
1、首先,随机去4个点,作为初始类簇中心。
2、计算所有样本点与这4个点的F相似度。根据相似程度,把所有样本点分到4个类中。
3、在这4个类中,计算每一个样本点 i 到该类其他样本点的相似度和Si。取Si最大的那个点作为这个类的中心。
4、重复2、3步骤,直到类中心不再变化或者循环次数达到目标。
2017-08-27-链家-算法-内推1面-现场
来了之后先做1个小时的题,5道算法题
因为比较长,所以采用 A:面试官 B:本人
B 自我介绍
A 你自己学机器学习,怎么学的?
B 自己看书,周志华的西瓜书、机器学习实战。先找着撸代码,然后去深究里面的理论。
A西瓜书看到什么程度?
B刚开始看,看不太懂,然后就以机器学习实战为主,先照着撸代码,然后去西瓜书里深究里面的理论。
B我给您说说SVM吧,自学的时候留下很深的印象(试图抓住主动权~)
SVM是基于。。。说着手动起来写SVM的损失函数
A (打断)为什么样本点到决策面是 1/||w||
B 手推向量点到决策面的表达式(麻蛋,竟然一时紧张忘了。。。没推出来)
A 点到直线距离公式记得吧?
B 嗯嗯,又没写出来。只能说之前推过,现在一紧张忘了。。。
A 这个也无关紧要,继续
B 继续说SVM
A (打断)知道LR吧,知道LR和SVM有什么不同吗?
B 知道,首先这两个算法的分类思想不同,LR是基于概率推导的,SVM是基于最大化几何间隔的
A (打断)写一下,LR的损失函数
B 手写出来。其实这个sigmoid函数由那个什么族分布(真的忘了名字,其实是:指数族分布),加上二项分布导出来的。损失函数是由最大似然估计求出的。
A 怎么由最大似然估计导出的?推导一下
B 最大似然估计就是求让已知事件发生的概率最大的参数。
假设有5个样本,每一个的类别是yi,由LR计算出的概率是h(x)。那么每一个样本预测正确的概率为:
(H(x)^yi)*((1-h(x))^(1-yi)) —-
(刚开始一紧张,把h(x)和yi写反了)面试官说是这样吗?你这样全为0,我感觉你在背公式。。。你再看看
我一看,卧槽这竟然写错了。赶紧改过来,然后表明是自己紧张了。
概率连乘后,然后取对数就是LR的损失函数了。
A 为什么损失函数有个负号?
B 这是因为要应用梯度下降法,引入的。不加负号也可以,梯度上升法。这都是一样的。
A OK,继续,LR和SVM有什么区别?
B SVM决策面只由少量的支持向量决定,而LR的话是所有样本都会参与决策面的更新。
A 对,所以说SVM怎么样?
B SVM对于异常点不敏感,而LR敏感。SVM更加健壮,决策面不受非支持向量影响。
A OK
A 知道过拟合吧?
B 知道,在训练集表现好,在测试集表现一塌糊涂。举个例子就是:学生平时考试成绩非常棒,但一到实际应用就很烂。
A 说说常见的过拟合的解决办法
B 数据,样本不够,如果现在的训练集只是所有样本空间的一个小小的部分,那么这个模型的泛化能力就非常差(边画图,边说)
A 嗯嗯,还有呢
B 可以加正则项,L1,L2正则。L1还可以用来选择特征
A 为什么L1可以用来选择特征
B 因为L1的话会把某些不重要的特征压缩为0
A 为什么L1可以把某些特征压缩为0
B 因为(画图)L1约束是正方形的,经验损失最有可能和L1的正方形的顶点相交,L1比较有棱角。所以可以把某些特征压缩为0
A 还有什么过拟合的解决方法
B 神经网络中,dropout方法。就是每层网络的训练,随机的让一半神经元不工作。达到防止过拟合的目的
A 还有吗?
B 决策树中可以用剪枝操作。
B 决策树过拟合,可以用随机森林。。。
A 什么???现在一个决策树已经过拟合了,还要再以它为基准训练随机森林?
B 。。。对,你说的对。我想错了。。。
B 我就知道这些方法了。。。
A OK,挑一个项目给我说说吧
B 说项目(不记得中间有没有再提问了。。。)
B 要不我给您说说spark框架吧,之前还用的挺多。
A 嗯(看简历和笔试题中。。。)
B 开始说。。。说到三分之一
A 好了! 你不必说了。(大手一挥~)我看你5道笔试题都没写思路,现在把第二题代码写出来
注: 第二题就是检测括号是否匹配
B 我写了啊。。。(给他翻到其中一个的背面)
A 哦,(迅速扫过代码,),为什要把字符压栈呢?不压栈也可以的。
B 是吗?{abc()}这样的也是合法的吗?
A 当然啊(看了一眼题。)
B 好吧,我本来也准备看到字符就丢到,不入栈。但担心这种情况不合法,就给入栈了。
A 嗯,第三题呢?
B 没思路,没写
A 给我说说第四题
第四题:10分钟内,恶意IP访问检测(10分钟内访问次数超过1024即为恶意访问)
B 这是10分钟动态检测的,需要时间刻度精确到秒吗?
A 不需要
B 把10分钟内的<ip,次数>存入hashmap, 再把key,value互换存入treemap。因为treemap是基于key有序的,升序。然后直接拿出来最后一个和1024比较。
A 怎么实现动态的检测,当前检测0-10分钟,那么第11分钟怎么办?
B 把0-10分钟的摘出来,从10分钟内的hashmap中减去,再把10-11分钟内的加上。
我知道这样实现起来,效率应该不高,但这一会我只想到了这个。。。
A 嗯,其实可以这样,把每分钟的分开存储,动态的向后移动,取这10个的总的数据就行。
甚至可以每分钟只存储TOP200的,然后10个分钟的汇总,取TOP1
B 嗯,明白了。
A 说说循环依赖这个怎么解决的?
第五题:系统有很多相互依赖的包,怎么检测循环依赖
B 把它当做一个链表。记录当前的名字在hashset中。如果某一次遍历的依赖名字存在于这个hashet中。就认为有循环依赖。
A 学过数据结构吧?学过图吧?给你一个有向图,怎么检测有环?
B 维护一个访问的数组,记录哪些点被访问过,从一点开始遍历,如果遍历的点被访问过,就说明有环
A 从哪个店开始遍历?
B 从入度为0的点开始遍历
A 如果有多个入度为0的点呢?
B 嗯。。。都要以它为入口开始遍历。
A show me the code!!!
(我内心是崩溃的。。。)
B 纠结了一会,又给他说了一遍思路。
A 嗯,好吧,我没有什么想问的了。你呢?
B 请问您说的这个图的这个应该怎么。。。算了,我还是下去自己看吧。。。我还是想知道怎么解决。。。
A 你说的对啊,就把思路给我讲了一下,和我的差不多。
B 贵公司这里机器学习、深度学习有什么应用场景呢?
A 房屋估价啊什么的。
B 好的,谢谢。再次感谢,离开。
2017-08-27-链家-算法-内推2面-现场
1、自我介绍
2、之前写过spark?写过统计日志用户数?那手写一下统计用户数(scala手写)
3、项目中用到了聚类?手写一下Kmeans
4、一般工业界不这样用,用kd-tree加速
5、给你出道题写一下,一个文件每一行有3列(\t分隔),每个字符串是abcd,这种形式,中间有大写有小写。
现认为:abcDe 等于BcaDe (即:不区分大小写,无关顺序)
要求输出: 字符 空格 出现次数 空格 每一种字符(以|分隔)
实例输出: abcde 2 abcDe|BcaDe
6、记不得了。。。好像没了。。。
2017-08-29-拼多多-算法-2面-内推-电话
1、自我介绍
2、将项目
3、说SVM
4、好像还说了spark原理
5、电话中断,面试官线上有BUG,去改BUG了。。。
6、10分钟后电话来了
7、我主动说:我给您说一下决策树方面的吧
8、面试官说:不用了,来道题。。。
9、一个矩阵都是0,1 且每一行,0都在1前面。求1个数最多的那一行的序号
2017-09-04-360-大数据算法-1面-内推-视频
1、自我介绍
2、说项目
3、说一下项目中用的Kmeans算法
4、知道哪几种聚类算法,说下原理
5、Kmeans有什么优缺点
6、项目用了RNN,说一下RNN原理
说了RNN原理,顺便说了LSTM/GRU的出现
7、为什么会出现长时依赖的问题
8、LSTM/GRU如何解决长时依赖的问题
9、写代码:
一个有序数组中查找某个数
一开始写了个遍历查找,面试官说,还能再快吗?
然后写了个二分查找
2017-09-05-美团点评-机器学习-1面-内推-电话
1、自我介绍
2、说项目
3、打断,问个扩展题:问答系统,有200W个FAQ,如何用分类模型做分类
思考ing,面试官提示:了解搜索引擎吗?
用倒排索引,把FAQ的问题分词,每个词对应多个FAQ。新来的query分词,每个词对应的FAQ拉出来。再在这个里面做分类。
4、继续说项目
5、说一下hadoop重要的2点
说shuffle,说map、reduce分别分配资源,可以细粒度控制资源占用情况,有利于超大任务平稳正常运行。
6、面试官说,其实是HDFS,正是由于有了分布式文件系统,才可以分布式计算
对,分布式文件系统。数据在哪里计算就在哪里,移动数据变成了移动计算。更高效
7、做题
给定二叉树前序、中序遍历结果。求后序遍历结果
8、一维空间中,2个线段,a1-b1 和a2-b2。判断是否两个线段有交集
他想要的答案是:一个线段里面的大坐标,小于等于另一个线段里面的小坐标。
2017-09-07-美团点评-机器学习-2面-内推-电话
1、自我介绍
2、说项目
3、用RNN了,说一下原理
说RNN,顺便说了长时依赖问题,介绍了LSTM,GRU
4、说情感分析的项目
5、每个句子都被打上标签正向或者负向情感,如果我想得出句子中的每个词的情感倾向,怎么做?
我不清楚该怎么做,就如下扯乎:
认为每个句子的情感倾向由每个词的情感倾向打分相加而得。
有的词正向:+1,+2,+3…
有的词负向:-1,-2,-3…
经过RNN,每一时刻的输出。。。扯完我现在想都想不通了。。。
后来想了想可以用贝叶斯分类。不知道对不对,还请大佬指正啊~
6、情感分析里用了SVM,说一下
说SVM,顺便跟LR对比一下
7、还知道其他分类算法吗
嗯嗯,知道,说了决策树,ID3,C4.5,再扯了扯bagging和boosting
8、做题
数轴上从左到右有n各点a[0], a[1], ……,a[n -1],给定一根长度为L的绳子,求绳子最多能覆盖其中的几个点。要求时间复杂度O(n),空间复杂度O(1)
2017-09-11-美团点评-机器学习-3面-内推-电话
1、自我介绍
2、说项目
3、场景题:一个景点有很多信息,位置、门票、类型等等。设计一个知识图谱。这个事情如果交给你来做,你会怎么推进
当时就一脸懵逼,只听过这个东西。没研究过。。。就硬着头皮瞎掰
4、我给介绍了SVM
5、你这机器学习这块,只学了这几个月。你认为你有什么优势能跟其他这个专业的人竞争?
麻蛋。。。确实没想过这个问题,继续瞎掰
6、又是场景题:有100亿网页,每个网页都有一个标签。有可能一个标签对应上百万标签,有的标签只对应几个标签。要做一个数据去重,每个标签只要1个网页。
7、工作中遇到了什么实际的难点问题,怎么解决的?
面试官是一个和蔼的秃顶大叔,估计是总监级别。问的问题就是有深度,考察解决问题能力
2017-09-11-搜狗-机器学习-1面-校招-现场
1、自我介绍
2、说项目
3、用RNN了,说一下原理
4、问RNN怎么训练的?
大概说了说,BPTT。这个不太懂
5、RNN的输入是什么呢?
有word2vec训练的词向量库,一个句子分词后,把词都换成对应的向量输入
6、继续说项目
7、项目用到聚类了?介绍一下
巴拉巴拉巴拉
8、说文本情感分类项目,文本向量用tf-idf这种有什么问题没有?
有,不能捕获到上下文之间的联系。以后尝试用doc2vec这种。
9、了解bagging和boosting吗?
巴拉巴拉
10、做题
1、全排列
2、数组第k大的数
3、数组左减右,求最大差
4、树的路径和
2017-09-17-百度-机器学习-1面-校招-现场
因为笔试做的比较烂,所以以为没有面试机会。于是去了现场企图霸面。结果小姐姐当场一查,居然我也在面试名单,是还没有通知。于是回去,愉快的等待第二天面试。
因为较长 A:面试官 B:本人
A你是上午最后一个,咱们可以多聊一会(内心是崩溃的。。。)
A(原本以为要套路的自我介绍。。。结果。。。)你用C++多吗?
B不多,用java、python较多
A那STL熟悉吗?
B不熟
A知道Trie树吗?
B不熟,一顿扯
A详细讲解Trie树。
A红黑树了解吗?(据说让搞红黑树就要挂,难道这里就是预兆???)
B说了说5个特性
A详细讲解红黑树、B树、2-3-4树。
B(一脸谦虚的认真听)
A来做道题
一副扑克牌,未拆封,是有序的排列。要给4个人发牌,要使发的每一张牌的概率相同。
即发第i次牌,发出10和发出2的概率要相等。
B想了想,问了问,说了说思路,谈论了一下。
A排序算法知道哪些
B巴拉巴拉
A快排了解吗?
B说了思想,说了如何划分集合。
A知道快排的非递归实现吗?
B不了解
A那写个mergeSort吧,规定要写代码的。
B一会就搞定了
A咱们问问机器学习吧
A随机森林了解吗?Bagging和boosting了解吗?
B介绍随机森林
A RF的话,如果有一个特征和标签特别强相关。选择划分特征时,如果不随机的从所用特征中随机取一些特征的话,那么每一次那个强相关特征都会被选取。那么每个数都会是一样的。这就是随机森林随机选取一些特征的作用,让某些树,不选这个强相关特征。
B搜嘎。。。
A知道为什么bagging吗?
B。。。
A bootstrap aggregating
B又介绍了boosting
A说说这个项目吧
B巴拉巴拉
A看你项目用了SVM,介绍一下
B巴拉巴拉(中间被打断)
A你们怎么过来说的都很像啊,你们都看什么书?
B。。。我看的周志华的西瓜书和李航的统计学习方法。。。
A继续
B。。。巴拉巴拉
A还用到了RNN,介绍一下
B巴拉巴拉
2017-09-19-三星研究所-机器学习-1 2 面-校招-现场
笔试:
早上笔试,一道题,3小时。。。
其实不是考编程,是考英语。。。
看题1小时,做题10分钟。。。
结束后,发了一张公交卡(32元)~管了一顿泡菜料理。。。
HR面试:
略。。。
技术面试:
1、介绍项目
2、介绍RNN
3、Python如何定义一个私有变量
4、Java多线程start和run方法的区别
5、Java hashmap和hashtable的区别
西安三星电子研究所说有关机器学习的有存储SSD方面的、物联网平台方面的
2018-01-25 回顾校招经验
知识储备(老生常谈):
计算机基础+算法题+专业知识基础(我就是机器学习基础)+项目
招聘内推信息:
水木社区+北邮人论坛+牛客网+等等等
海投,看准岗位。
能提前实习就实习,能内推就内推。因为坑位一步一步变少嘛
面试前经验:在牛客网上搜索该公司的面经,把和自己岗位有关的知识点,记录下来,搞懂。
面试中经验:当气氛尴尬时,就是你回答了他的问题后,他还没有提出下一个问题时。抢占先机,想他兜售、推销你准备好的、熟练的知识。
HR面试经验:当HR问你,那个XXX公司怎么样啊,他让你去,你怎么选择呢?
个人感觉(仁者见仁智者见智):客观的表达自己的观点,不能因为参加A公司的面试,就当场贬低B公司。但是,有一点很重要, 一定要说出一个听起来让人信服的理由,自己想加入A公司而不是B公司的理由。
==================== 面试常问的深度学习(DNN、CNN、RNN)的相关问题 ===
神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/稀疏的空间去分类/回归。增加节点数:增加维度,即增加线性转换能力。增加层数:增加激活函数的次数,即增加非线性转换次数。
对卡在局部极小值的处理方法:
1.调节步伐:调节学习速率,使每一次的更新“步伐”不同;2.优化起点:合理初始化权重(weights initialization)、预训练网络(pre-train),使网络获得一个较好的“起始点”,如最右侧的起始点就比最左侧的起始点要好。常用方法有:高斯分布初始权重(Gaussian distribution)、均匀分布初始权重(Uniform distribution)、Glorot 初始权重、He初始权、稀疏矩阵初始权重(sparse matrix)。
浅层VS深层:
浅层神经网络可以模拟任何函数,但数据量的代价是无法接受的。深层解决了这个问题。相比浅层神经网络,深层神经网络可以用更少的数据量来学到更好的拟合。深层的前提是:空间中的元素可以由迭代发展而来的。
防止过拟合:
L2正则化,Dropout(若规律不是在所有样本中都存在,则dropout会删除这样的规律),每个epoch之后shuffle训练数据,设置early-stopping。加Batch Normalization(BN首先是把所有的samples的统计分布标准化,降低了batch内不同样本的差异性,然后又允许batch内的各个samples有各自的统计分布),BN最大的优点为允许网络使用较大的学习速率进行训练,加快网络的训练速度(减少epoch次数),提升效果。
为何使用Batch Normalization:
若用多个梯度的均值来更新权重的批量梯度下降法可以用相对少的训练次数遍历完整个训练集,其次可以使更新的方向更加贴合整个训练集,避免单个噪音样本使网络更新到错误方向。然而也正是因为平均了多个样本的梯度,许多样本对神经网络的贡献就被其他样本平均掉了,相当于在每个epoch中,训练集的样本数被缩小了。batch中每个样本的差异性越大,这种弊端就越严重。一般的解决方法就是在每次训练完一个epoch后,将训练集中样本的顺序打乱再训练另一个epoch,不断反复。这样重新组成的batch中的样本梯度的平均值就会与上一个epoch的不同。而这显然增加了训练的时间。同时因为没办法保证每次更新的方向都贴合整个训练集的大方向,只能使用较小的学习速率。这意味着训练过程中,一部分steps对网络最终的更新起到了促进,一部分steps对网络最终的更新造成了干扰,这样“磕磕碰碰”无数个epoch后才能达到较为满意的结果。
为了解决这种“不效率”的训练,BN首先是把所有的samples的统计分布标准化,降低了batch内不同样本的差异性,然后又允许batch内的各个samples有各自的统计分布。
为什么神经网络高效:并行的先验知识使得模型可用线性级数量的样本学习指数级数量的变体
学习的本质是什么:将变体拆分成因素和知识(Disentangle Factors of Variation)
i. 为什么深层神经网络比浅层神经网络更高效:迭代组成的先验知识使得样本可用于帮助训练其他共用同样底层结构的样本。
ii. 神经网络在什么问题上不具备优势:不满足并行与迭代先验的任务
- 非迭代:该层状态不是由上层状态构成的任务(如:很深的CNN因为有max pooling,信息会逐渐丢失。而residual network再次使得迭代的先验满足)
CNN:
1)卷积:对图像元素的矩阵变换,是提取图像特征的方法,多种卷积核可以提取多种特征。一个卷积核覆盖的原始图像的范围叫做感受野(权值共享)。一次卷积运算(哪怕是多个卷积核)提取的特征往往是局部的,难以提取出比较全局的特征,因此需要在一层卷积基础上继续做卷积计算 ,这也就是多层卷积。
2)池化:降维的方法,按照卷积计算得出的特征向量维度大的惊人,不但会带来非常大的计算量,而且容易出现过拟合,解决过拟合的办法就是让模型尽量“泛化”,也就是再“模糊”一点,那么一种方法就是把图像中局部区域的特征做一个平滑压缩处理,这源于局部图像一些特征的相似性(即局部相关性原理)。
3) 全连接:softmax分类
训练过程:
卷积核中的因子(×1或×0)其实就是需要学习的参数,也就是卷积核矩阵元素的值就是参数值。一个特征如果有9个值,1000个特征就有900个值,再加上多个层,需要学习的参数还是比较多的。
CNN的三个优点:
sparse interaction(稀疏的交互),parameter sharing(参数共享),equivalent respresentation(等价表示)。适合于自动问答系统中的答案选择模型的训练。
CNN与DNN的区别:
DNN的输入是向量形式,并未考虑到平面的结构信息,在图像和NLP领域这一结构信息尤为重要,例如识别图像中的数字,同一数字与所在位置无关(换句话说任一位置的权重都应相同),CNN的输入可以是tensor,例如二维矩阵,通过filter获得局部特征,较好的保留了平面结构信息。
filter尺寸计算:Feature Map的尺寸等于(input_size + 2 * padding_size − filter_size)/stride+1
RNN:
- 为什么具有记忆功能?
这个是在RNN就解决的问题,就是因为有递归效应,上一时刻隐层的状态参与到了这个时刻的计算过程中,直白一点呢的表述也就是选择和决策参考了上一次的状态。 - 为什么LSTM记的时间长?
因为特意设计的结构中具有CEC的特点,误差向上一个状态传递时几乎没有衰减,所以权值调整的时候,对于很长时间之前的状态带来的影响和结尾状态带来的影响可以同时发挥作用,最后训练出来的模型就具有较长时间范围内的记忆功能。
误差回传的主力还是通过了Memory Cell而保持了下来。所以我们现在用的LSTM模型,依然有比较好的效果。
最后整个梳理一下误差回传的过程,误差通过输出层,分类器,隐层等进入某个时刻的Block之后,先将误差传递给了Output Gate和Memory Cell两个地方。
到达输出门的误差,用来更新了输出门的参数w,到达Memory Cell之后,误差经过两个路径,
1是通过这个cell向前一个时刻传递或者更前的时刻传递,
2是用来传递到input gate和block的输入,用来更新了相应的权值(注意!不会经过这里向前一个时刻传递误差)。
最关键的问题就是,这个回传的算法,只通过中间的Memory Cell向更前的时刻传递误差。
在RNN中U、V、W的参数都是共享的,也就是只需要关注每一步都在做相同的事情,只是输入不同,这样来降低参数个数和计算量。
RNN特点:
时序长短可变(只要知道上一时刻的隐藏状态ht−1ht−1与当前时刻的输入xtxt,就可以计算当前时刻的隐藏状态htht。并且由于计算所用到的WxhWxh与WhhWhh在任意时刻都是共享的。递归网络可以处理任意长度的时间序列)顾及时间依赖,未来信息依赖(双向递归)
RNN主要包括LSTM,GRU
GRU对LSTM做了两个大改动:
将输入门、遗忘门、输出门变为两个门:更新门(Update Gate)和重置门(Reset Gate)。
将单元状态与输出合并为一个状态:。
GRU只用了两个gates,将LSTM中的输入门和遗忘门合并成了更新门。并且并不把线性自更新建立在额外的memory cell上,而是直接线性累积建立在隐藏状态上,并靠gates来调控。
博主作为一名应届生,进入阿里做推荐算法,得益于对tensorflow的了解。
在阿里的日子里主要做基于word2vec的召回算法,doc2vec的排序算法,表征技术REPL的纯ID类排序算法,基于DNN的长短期记忆模型和追剧模型。
它山之石
数据库篇
众人拾柴火焰高
在众人拾柴的场景中,必须会同时用java和c++答题,必须具有java和c++相互改写的能力(原因你懂的)在面试中,则必须具有基础知识(王道4件套)+当场解决算法题的能力
行测题
是的,网易、阿里等居然在人才测评中考行测题。推荐粉笔APP