
导语
在上一篇中笔者准备了100w条新闻语料,接下来进入文本分类的预处理环节。当然,进行文本分类需要遵循一些基本步骤,以下便是笔者总结的文本分类的基本处理框架(持续更新本框架):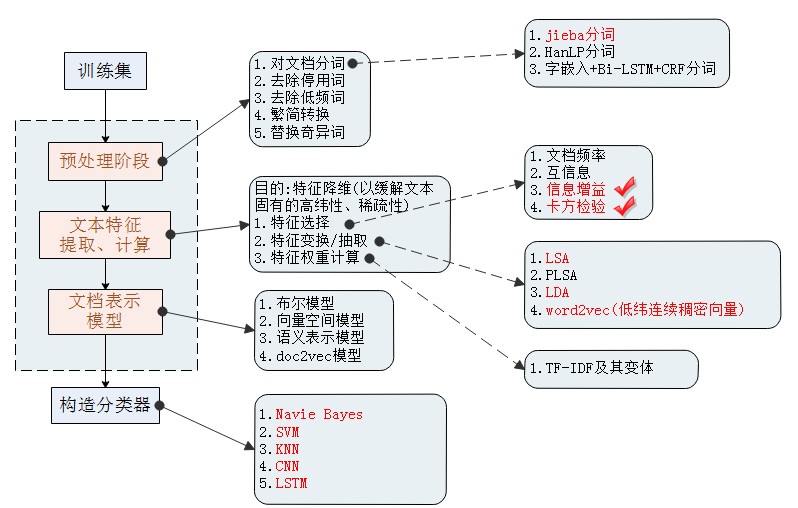
预处理阶段
分词方案
NLP中分词是一项基础技术,分词好坏对后续各项NLP任务也有不小的影响。目前的常用分词方案如下: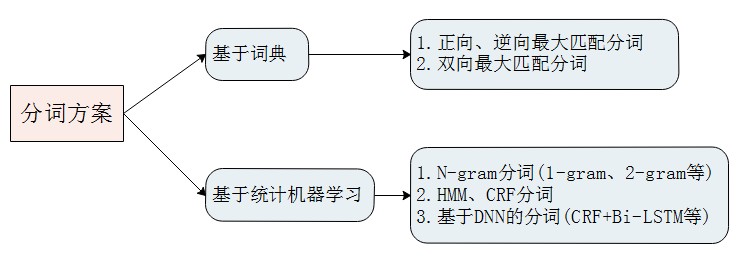
对中文分词的讨论可以参考有哪些比较好的中文分词方案?
值得注意的是,常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性,比如分词器支持用户自定义词典。
目前比较成熟的分词器有多款,笔者决定在项目中采用jieba分词。
首先来看一下jieba分词的部分词性表,更完整的见jieba(结巴)分词种词性简介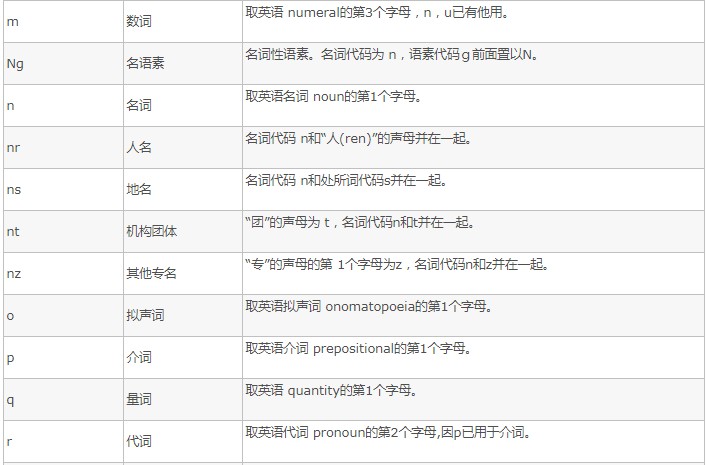
对于新闻文本分类来说,名词最能突出该新闻表达的主旨,所以对新闻文本使用jieba进行带词性的分词后,需要过滤掉其它非名词,特别要过滤掉单个字,数量词和人名等。 其中,可以利用百家姓氏表,去除包含这些姓氏的人名。
去除停用词
停用词就是频繁出现,但没有意义的虚词或者是与文本类型特征信息无关或者明显关联度很低的词。笔者在这里采用哈工大停用词表,过滤非名词和去除停用词可以在分词时一起进行。
去除低频词
词频为1或2 的低频词与文档的关联度较低,但在文中所占比重约为 2/3 ,在预处理过程中对低频词进行去噪,可在保证文本挖掘精度的前提下,大大减少特征维度,使时空复杂度明显下降.
繁简转换
取决于当前文本任务是否需要
替换奇异词
由于新闻相对正规,所以奇异词很少出现,但如果需要处理网友评论等文本时,因为敏感词或者其它原因,文本中会出现大量的奇异词。比如:
replace_dict = {
u'吻腚':u'稳定',
u'弓虽':u'强',
u'女干':u'奸',
u'示土':u'社',
u'禾口':u'和',
u'言皆':u'谐',
u'释永性':u'释永信',
u'大菊观':u'大局观',
u'yl':u'一楼',
u'cnm':u'草泥马',
u'CCTV':u'中央电视台',
u'CCAV':u'中央电视台',
u'ccav':u'中央电视台',
u'cctv':u'中央电视台',
u'qq':u'腾讯聊天账号',
u'QQ':u'腾讯聊天账号',
u'cctv':u'中央电视台',
u'CEO':u'首席执行官',
u'克宫':u'克里姆林宫',
u'PM2.5':u'细颗粒物',
u'pm2.5':u'细颗粒物',
u'SDR':u'特别提款权',
u'装13':u'装逼',
u'213':u'二逼',
u'13亿':u'十三亿',
u'巭':u'功夫',
u'孬':u'不好',
u'嫑':u'不要',
u'夯':u'大力',
u'芘':u'操逼',
u'烎':u'开火',
u'菌堆':u'军队',
u'sb':u'傻逼',
u'SB':u'傻逼',
u'Sb':u'傻逼',
u'sB':u'傻逼',
u'is':u'伊斯兰国',
u'isis':u'伊斯兰国',
u'ISIS':u'伊斯兰国',
u'ko':u'打晕',
u'你M':u'你妹',
u'你m':u'你妹',
u'震精':u'震惊',
u'返工分子':u'反共',
u'黄皮鹅狗':u'黄皮肤俄罗斯狗腿',
u'苏祸姨':u'苏霍伊',
u'混球屎报':u'环球时报',
u'屎报':u'时报',
u'jb':u'鸡巴',
u'j巴':u'鸡巴',
u'j8':u'鸡巴',
u'J8':u'鸡巴',
u'JB':u'鸡巴',
u'瞎BB':u'瞎说',
u'nb':u'牛逼',
u'牛b':u'牛逼',
u'牛B':u'牛逼',
u'牛bi':u'牛逼',
u'牛掰':u'牛逼',
u'苏24':u'苏两四',
u'苏27':u'苏两七',
u'痰腐集团':u'贪腐集团',
u'痰腐':u'贪腐',
u'反hua':u'反华',
u'屋猫':u'五毛',
u'5毛':u'五毛',
u'傻大姆':u'萨达姆',
u'霉狗':u'美狗',
u'TMD':u'他妈的',
u'tmd':u'他妈的',
u'japan':u'日本',
u'P民':u'屁民',
u'八离开烩':u'巴黎开会',
u'傻比':u'傻逼',
u'潶鬼':u'黑鬼',
u'cao':u'操',
u'爱龟':u'爱国',
u'天草':u'天朝',
u'灰机':u'飞机',
u'张将军':u'张召忠',
u'大裤衩':u'中央电视台总部大楼',
u'枪毕':u'枪毙',
u'环球屎报':u'环球时报',
u'环球屎包':u'环球时报',
u'混球报':u'环球时报',
u'还球时报':u'环球时报',
u'人X日报':u'人民日报',
u'人x日报':u'人民日报',
u'清只县':u'清知县',
u'PM值':u'颗粒物值',
u'TM':u'他妈',
u'首毒':u'首都',
u'gdp':u'国内生产总值',
u'GDP':u'国内生产总值',
u'鸡的屁':u'国内生产总值',
u'999':u'红十字会',
u'霉里贱':u'美利坚',
u'毛子':u'俄罗斯人',
u'ZF':u'政府',
u'zf':u'政府',
u'蒸腐':u'政府',
u'霉国':u'美国',
u'狗熊':u'俄罗斯',
u'恶罗斯':u'俄罗斯',
u'我x':u'我操',
u'x你妈':u'操你妈',
u'p用':u'屁用',
u'胎毒':u'台独',
u'DT':u'蛋疼',
u'dt':u'蛋疼',
u'IT':u'信息技术',
u'1楼':u'一楼',
u'2楼':u'二楼',
u'2逼':u'二逼',
u'二b':u'二逼',
u'二B':u'二逼',
u'晚9':u'晚九',
u'朝5':u'朝五',
u'黄易':u'黄色网易',
u'艹':u'操',
u'滚下抬':u'滚下台',
u'灵道':u'领导',
u'煳':u'糊',
u'跟贴被火星网友带走啦':u'',
u'猿们':u'公务员们',
u'棺猿':u'官员',
u'贯猿':u'官员',
u'每只猿':u'每个公务员',
u'巢县':u'朝鲜',
u'死大林':u'斯大林',
u'无毛们':u'五毛们',
u'天巢':u'天朝',
u'普特勒':u'普京',
u'依拉克':u'伊拉克',
u'歼20':u'歼二零',
u'歼10':u'歼十',
u'歼8':u'歼八',
u'f22':u'猛禽',
u'p民':u'屁民',
u'钟殃':u'中央'
}
代码实现
注意:每类新闻语料有10W条,每条新闻按照时间顺序依次标号,其中5W条用来训练,剩余5W条用来测试。考虑到随着时间变迁,新生事物不断出现,我们不能简单的取前5W条进行训练,后5W条进行测试。这里,我们采用标号为奇数的做训练集,标号为偶数的做测试集。 采用以下代码依次对10类新闻语料进行预处理,保存预处理结果。
#对某个新闻类别下的语料进行分词和去停用词
#-*- encoding: utf-8 -*-
import jieba
import jieba.posseg as pseg
def CreatStopWords(stoprWordsPath):
with open(stoprWordsPath,encoding='utf-8') as writer:
stopWords=set()
for aLine in writer:
stopWords.add(aLine.strip('\n'))
return stopWords
def Cutting(DictPath,OutPath,StartNum,EndNUm,stopWords):
StartNum=StartNum+1
for index in range(StartNum,EndNUm+1):
if(index%2 != 0):
FilePath=DictPath+'/'+str(index)+'.txt'
OutFilePath=OutPath+'/'+str(index)+'.txt'
f1 = open( FilePath, 'r', encoding='UTF-8')
f2 = open(OutFilePath, 'w', encoding='UTF-8')
fs = f1.read()
result = pseg.cut(fs)
Resstring = ""
for w in result:
# 去除非名词和停用词
if w.flag.startswith("n") and (w.flag != 'nr') and (w.word not in stopWords):
Resstring = Resstring + w.word + " "
# print (w.word, w.flag)
f2.write(Resstring + '\n')
def main():
DictPath="E:/TEXTCRAWER/yl/corpus"
OutPath="E:/TEXTCRAWER/yl/CutRes_test"
StopWordsPath='E:/TEXTCRAWER/auto/stopWords'
StartNum=0
EndNUm=99999
stopWords=CreatStopWords(StopWordsPath)
Cutting(DictPath,OutPath,StartNum,EndNUm,stopWords)
#print("Over cutting words")
if __name__ == '__main__':
main()
特征选择
经过预处理后,文本集合中保留下来的特征词还是很多,特征维度过高,增加分类计算复杂度,也存在大量噪音,不利于分类精度的提高。于是需要进行文本特征的提取已达到去粗取精的效果。特征提取的目的就是特征降维,克服文本固有的高纬性、高稀疏性的缺点,选出对分类最有帮助的特征词集合。
特征降维方式从2个大的立场切入:
- 特征选择 (在词义空间中表达特征,不考虑特征的语义)
- 特征变换/抽取 (在语义空间中表达特征,考虑特征的语义)
常用的几个特征选择准则总结如下:
文档频率
文档频率 指某个特征词在训练集中出现的文档数。我们可以统计出每个特征词的文档频率值,再按照预先设定的阈值,去除低于阈值的特征词。
互信息
互信息(Mutual Information,MI) 用于度量某个特征词与特定类别的共现程度,计算公式如下: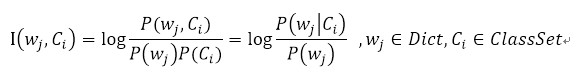
当两者近似无关时,
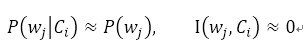
对于新闻文本这一个多分类问题,我们可以计算该特征词与所有类别的期望互信息来度量该特征词对分类差异的重要性,依次计算出每个特征词的互信息,最后按照计算值进行排序选择特征词。
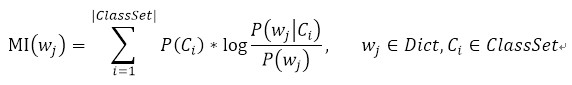
缺点分析: 互信息实际中并不是一个很好的文本选择准则,因为从上述公示中可以看出,对于比较孤僻的特征词,P(wj)会很小,导致计算值很大。 因此,互信息倾向于选择那些频率较低的特征词,但实际上只有选择那些在某一类中比较频繁地出现但是在其他类下很少出现的词作为特征项,才能达到不错的分类效果。
信息增益
先插入一点关于信息熵的背景知识
条件熵H(Y|X)是在已知随机变量X的所有概率分布取值的条件下对随机变量Y的不确定性的度量。
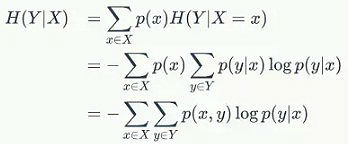
通俗一点就是,当我们完全洞悉随机变量X的概率分布后,它对我们度量随机变量Y有多少帮助。假如,X和Y是独立的,则根据上述公式得到H(Y|X)=H(Y),知道X的分布对度量Y并没有什么好处。而如果X和Y高度相关,乃至于Y=X,则此时H(Y|X)=H(X),则此时我们可以完全度量Y。
信息增益(Information Gain,IG) 度量某个特征的存在与否能够为分类系统带来多少信息量的差异,带来的信息越多,那么该特征就越重要。推导如下:

缺点分析: 信息增益本质就是计算引入特征项前后的类别随机变量C的熵差,而熵的计算是针对整个分类系统而言的,所以,信息增益只能判断该特征对所有类别的重要性,所有类别共享一套特征集合,而无法计算该特征与具体某个类别的关系,与卡方检验相比处理粒度不够细。
卡方检验
卡方检验(Chi’s Test, Chi) 是相对不错的特征选择准则,它也是本项目采用的准则。卡方检验在统计中常用于检验2个随机变量是否独立,其基本思想是观察实际值和理论值的偏差来确定理论的正确性,具体做的时候常常先假设两个变量确实是独立的(“原假设”),然后观察实际值(观察值)与理论值(这个理论值是指“如果两者确实独立”的情况下应该有的值)的偏差程度,如果偏差足够小,我们就认为误差是很自然的样本误差,是测量手段不够精确导致或者偶然发生的,两者确确实实是独立的,此时就接受原假设;如果偏差大到一定程度,使得这样的误差不太可能是偶然产生或者测量不精确所致,我们就认为两者实际上是相关的,即否定原假设,而接受备择假设。

回到文本特征选择中,对于当前特征 wj 和特定类别 Ci ,假设我们统计语料后得到下面这张表格:
说明:
N :训练集文档总数
A :包含wj,同时属于类别Ci的文档计数
B :包含wj,但不属于类别Ci的文档计数
C :不包含wj,但属于类别Ci的文档计数
D :不包含wj,同时不属于类别Ci的文档计数
| Chi’s Test | 属于类别Ci | 不属于类别Ci | 总计 |
|---|---|---|---|
| 含特征wj | A | B | A+B |
| 不含特征wj | C | D | C+D |
| 总计 | A+C | B+D | N=A+B+C+D |
则计算某个特征词wj和某个类别Ci的Chi值公式为: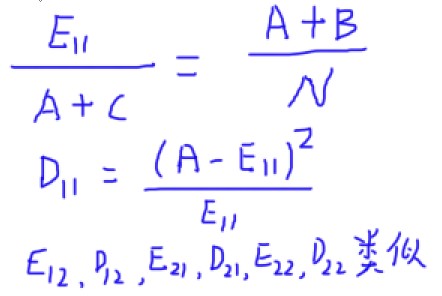
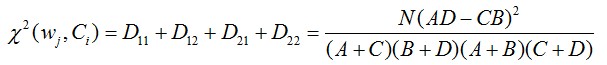
按照下图利用上述公式计算词典中的每个特征词和每个类别的Chi值: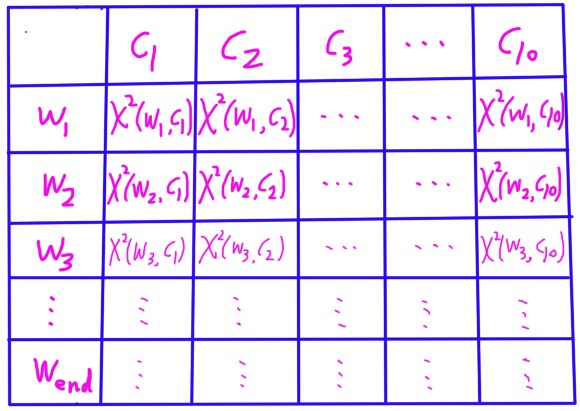
其算法伪代码如下: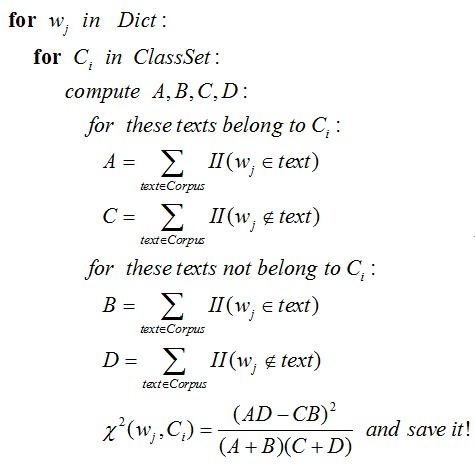
卡方检验代码实现
对训练文本进行卡方检验计算
# encoding=utf-8
import math
import time
from operator import itemgetter
WordInCate = {}
CatoDocsNumber = { #
0: 50000,
1: 50000,
2: 50000,
3: 50000,
4: 50000,
5: 50000,
6: 50000,
7: 50000,
8: 50000,
9: 50000,
10: 500000
}
# the line of word belong to which cate
def cateIdx(lineNum):
return math.floor(lineNum/50000)
# for wordsStatistics
def wordsStatistics(trainfile):
with open(trainfile, 'r', encoding='utf-8') as f:
lineNum = 0
for line in f:
lineNum += 1
cate = cateIdx(lineNum)
for word in set(line.split()):
if (word not in WordInCate):
WordInCate[word] = {cate:1} # the word appears for the first time
else:
if (cate in WordInCate[word]): # the word-cate has been there
WordInCate[word][cate] += 1 # the word has been there but word-cate appears for the first time
else:
WordInCate[word][cate] = 1
# output.txt
def outputFile(outputfile):
with open(outputfile,'w',encoding='utf-8') as f:
for word, cateCnt in WordInCate.items():
f.write(word+' ')
for cate, cnt in cateCnt.items():
f.write(str(cate)+':'+str(cnt)+' ')
f.write('\n')
# calculate total appear time for a word in all docs
def totalForAWord():
for word, cateCnt in WordInCate.items():
wordTotal = 0
for cnt in cateCnt.values():
wordTotal += cnt
WordInCate[word][10] = wordTotal
# get top chisquare words in each catogory
def getTop(ChisForOneCate):
top = sorted(ChisForOneCate, key=itemgetter(1, 0),reverse=True)
return top[0:5000] #
# output chisquare to file
def chisOutput(cate, top):
with open('D:/TextClassify/50W测试集/chis'+str(cate)+'.txt', 'w', encoding='utf-8') as f:
for wordChis in top:
f.write(wordChis[0] + ':'+str(wordChis[1])+'\n')
# calculate chisquare
def chisquareTest():
N=CatoDocsNumber[10]
for cate in range(0,(len(CatoDocsNumber)-1)):
ChisForOneCate = set()
M=CatoDocsNumber[cate]
for word in WordInCate:
if (cate in WordInCate[word]):
A= WordInCate[word][cate]
B= WordInCate[word][10]-A
C= M-A
D= N-M-B
if((A + B)*(A + C)*(B + D)*(C + D)==0 or (A * D - B * C)<=0):
chisquare=0
else:
chisquare = (N * pow((A * D - B * C),2)) / ((A + B)*(A + C)*(B + D)*(C + D))
ChisForOneCate.add((word, chisquare))
else:
pass
top = getTop(ChisForOneCate)
chisOutput(cate, top)
if __name__ == '__main__':
print("start :", time.time())
DictPath = "train50W.txt"
wordsStatistics(DictPath)
totalForAWord()
OutPath = "word_Cate_docsCnt2.txt"
outputFile(OutPath)
chisquareTest()
print("finish :", time.time())
进行卡方检验后,我们分别得到10个文本,分别对应这10个类别下每个单词和该类别的chi值。
例如: 财经类对应的Chi值如下: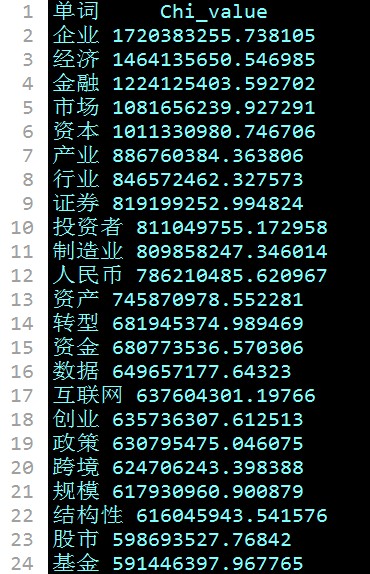
小结
在本篇文章中,笔者主要详细描述了文本的预处理阶段中的若干环节和几种文本特征选择方法,并给出了本项目中针对若干环节的实践代码。
需要指出,文本预处理和特征提取方法对后续分类器正确分类有至关重要的影响,随着后续项目的进行和笔者经验的不断积累,可以适时地将心得体会记录在这篇文章中,不断完善本篇文章。
至于文本特征变换/抽取的若干方法在后续文章中会详细讲到。那么在下一篇文章中,笔者打算实战朴素贝叶斯分类器用于我们的新闻文本分类。